진행하고 있는 프로젝트의 이미지가 회색조인데 3차원으로 입력을 했었습니다. 그랬더니 모델이 사진에서 의미있는 feature를 추출하지 못하는 듯한 모습을 보여서, 아예 input image를 grayscale로 변경하여 실험을 하였습니다. 이렇게 3차원으로 만들어진 Pytorch의 모델들을 어떻게 1차원 이미지로 학습시켜야 하는지 그 방법에 대해 알아보겠습니다.
저는 pre-trained되지 않은 모델을 사용하였습니다. Pytorch에서 모델만 불러와서 실험을 하였습니다.
1. 첫 번째 레이어의 입력값 변경해주기
네 번째 인턴일지를 보신 분들은 아시겠지만, CNN의 특징맵 벡터의 사이즈를 결정하는 것은 channel입니다. 그래서 CNN의 첫 번쨰 레이어 입력값은 내가 가진 데이터의 channel이 된다고 보시면 됩니다. 대부분 3차원인 컬러 사진을 CNN의 입력값으로 주기 때문에, 사진을 다루는 CNN 모델들 또한 첫 번째 레이어의 입력값이 3으로 되어있습니다.

Conv2d(input_channel, output_channel, ...)을 의미합니다. 즉, ResNet의 입력 이미지가 3채널(=컬러) 이미지여야 한다는 말입니다. 우리가 흑백사진을 input으로 넣고 오류를 만나지 않기 위해서는 이 첫 번째 레이어의 입력 채널을 1로 변경해주어야 합니다.
self.model = models.resnet50()
self.model.conv1 = nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) #흑백사진 학습 위해 input shape 변경
2. weight파일 channel 변경해주기
사실 저도 1번과 같이 하면 끝인 줄 알았습니다. 그런데, input layer만 변경해서 학습을 진행하니 모델의 출력값이 너무 안좋았습니다.


loss graph와 accuracy 그래프가 너무 튀어서 이건 잘못되었다 싶었습니다...
열심히 구글링을 해 본 결과, 첫 번째 레이어의 weight 모양도 변경해주어야 한다는 것을 알게 되었습니다.
보통 이렇게 pytorch에서 불러와서 모델을 사용할 경우엔 pretrained 모델에 전이학습을 하는데, 이 모델을 학습시킬 땐 컬러 이미지로 학습을 시켰기 때문에 그냥 입력층만 바꿔주면 오류는 생기지 않아도 결과 자체는 이상하게 나오는 것이었습니다.
그래서 첫 번쨰 입력층의 weight 값의 모양 또한 변경해주었습니다.
self.model.conv1.weight.data = self.model.conv1.weight.data.sum(axis=1).reshape(64,1,7,7)전체 모델 코드는 다음과 같습니다.
class ResNetClassifier(nn.Module):
def __init__(self):
super(ResNetClassifier, self).__init__()
'''resnet'''
self.model = models.resnet50(pretrained=True)
self.model.conv1 = nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False) #흑백사진 학습 위해 input shape 변경
self.model.conv1.weight.data = self.model.conv1.weight.data.sum(axis=1).reshape(64,1,7,7)
self.in_feature = self.model.fc.in_features
self.model.fc = nn.Linear(self.in_feature, self.in_feature) # fc를 일반 항등함수처럼 사용하여 모델이 의미없이 지나가도록 함
self.classifier = nn.Sequential(
nn.Linear(in_features=self.in_feature*4+2, out_features= 64),
nn.ReLU(inplace=True),
nn.Linear(in_features=64, out_features= 32),
nn.ReLU(inplace=True),
nn.Linear(in_features=32, out_features= 8),
nn.ReLU(inplace=True),
nn.Linear(in_features=8, out_features=1),
nn.Sigmoid()
)
def forward(self, image1,image2, image3, image4, num1, num2):
image1 = self.model(image1)
image2 = self.model(image2)
image3 = self.model(image3)
image4 = self.model(image4)
images1 = torch.cat([image1,image2],dim=1) #batch기준으로 concat
images2 = torch.cat([image3,image4],dim=1) #batch기준으로 concat
images = torch.cat([images1,images2],dim=1)
input = torch.cat([images,num1],dim=1)
input = torch.cat([input,num2],dim=1)
output = self.classifier(input)
return output저는 이미지 네 개의 feature map을 추출하고 그 feature map과 숫자 두 개를 합해 classifier를 진행하는 모델을 만들었습니다. 각자 상황에 맞게 forward 함수와 classifer를 수정하시면 됩니다.
최종 결과 loss와 accuracy는 다음과 같습니다.

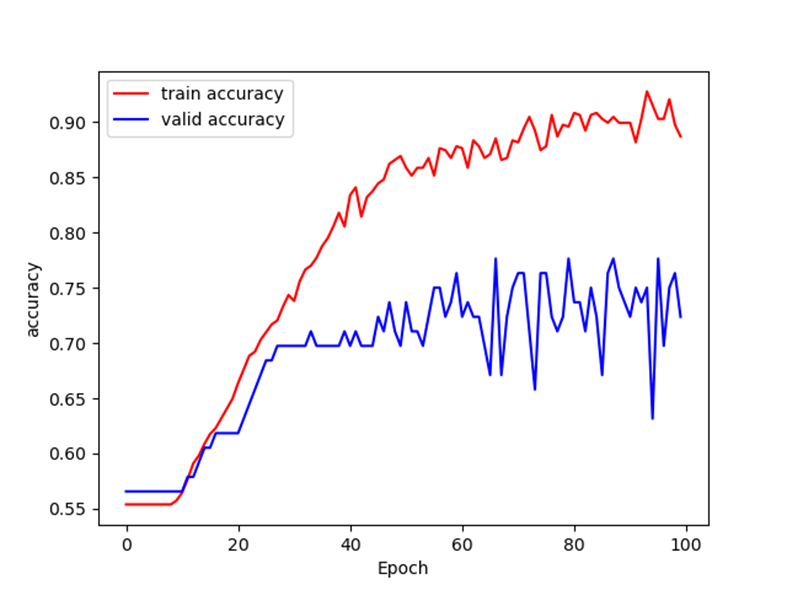
확실히 위에서 했던 실험보다는 낙차가 조금 생기긴 했습니다.. 이제 learning rate schedular 등 여러 다른 하이퍼 파라미터를 변경하여 실험 결과가 안정적으로 나오도록 수정해야 할 듯 싶습니다.
이상으로 포스팅 마치겠습니다:)
'인턴일지' 카테고리의 다른 글
| [인턴일지] 일곱번째 인턴일지 : 전이학습 (1) | 2023.11.20 |
|---|---|
| [인턴일지] 여섯번째 인턴일지 : 7개월 중 3개월이 지난 시점의 회고록 (0) | 2023.11.07 |
| [인턴일지] 네 번째 인턴일지: CNN(Convolution Neural Network) 직접 구성하기 (2) | 2023.10.24 |
| [인턴일지] 세 번째 인턴일지 : ROC curve (0) | 2023.10.06 |
| [인턴일지] 두 번째 인턴일지: BInary Classification(이진 분류) (0) | 2023.09.26 |