그동안 직접 만든 CNN으로 계속 학습시키고, 결과를 노션에 혼자 정리했더니 블로그에 기록할 일이 많이 없었습니다. 그러던 중, CNN의 결과가 너무 안나와서 ResNet과 DenseNet을 전이학습해서 해보자는 조언을 얻어서, 이렇게 전이학습에 대해 포스팅을 하게 되었습니다!
기존 CNN
일단, 지금 내가 사용하고 있는 CNN은 다음과 같습니다
class ClassificationModel(nn.Module):
'''CNN 직접 쌓아 만든 모델'''
def __init__(self):
super(ClassificationModel, self).__init__()
self.feature_extraction = nn.Sequential(
# [batch_size, 512,512,1] -> [batch_size, 510,510,8]
nn.Conv2d(in_channels=1, out_channels=8, kernel_size=3),
nn.ReLU(inplace=True),
# [batch_size, 510,510,8] -> [batch_size, 255,255,8]
nn.MaxPool2d(kernel_size=2, stride=2),
nn.BatchNorm2d(8),
# [batch_size, 255,255,8] -> [batch_size, 253,253,16]
nn.Conv2d(in_channels=8, out_channels=16, kernel_size=3),
nn.ReLU(inplace=True),
# [batch_size, 253,253,16] -> [batch_size, 126,126,16]
nn.MaxPool2d(kernel_size=2, stride=2),
nn.BatchNorm2d(16),
# [batch_size, 126,126,16] -> [batch_size, 124,124,32]
nn.Conv2d(in_channels=16, out_channels=32,kernel_size=3),
nn.ReLU(inplace=True),
# [batch_size, 124,124,32] -> [batch_size, 62,62,32]
nn.MaxPool2d(kernel_size=2, stride=2),
nn.BatchNorm2d(32),
#[batch_size, 62,62,32] -> [batch_size, 60,60,64]
nn.Conv2d(in_channels=32, out_channels=64,kernel_size=3),
nn.ReLU(inplace=True),
# [batch_size, 60,60,64] -> [batch_size, 30,30,64]
nn.MaxPool2d(kernel_size=2, stride=2),
nn.BatchNorm2d(64)
)
self.flatten_layer = nn.Flatten()
self.classifier = nn.Sequential(
nn.Linear((30*30*64)*4+2, 128),
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.Dropout(0.3),
nn.Linear(128,1),
nn.Sigmoid()
)가장 마지막으로 실험한 모델입니다. 이렇게 CNN으로 실험하면서 가장 신기했던 것은, Convolution layer와 maxpooling layer가 하나씩 늘어날 때 마다, 정확도가 올라가고, 모델이 뱉어낸 테스트 결과가 점점 안정적이라는 것이었습니다.
그러나 이마저도 한계에 부딛혔습니다.
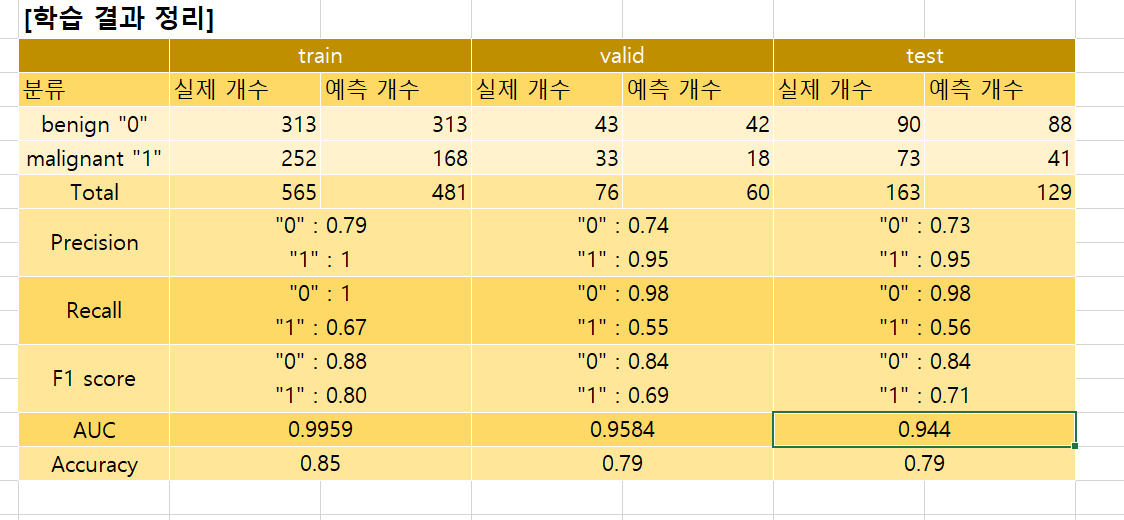

이게 그냥 학교 과제 프로젝트라면 정확도 83퍼도 나쁘진 않은 결과이다. 그러나, 회사에서 인턴 프로젝트로 진행하는 만큼, 정확도 95%를 목표로 하고 있다. 근데 83%라니...... 말이 안되지 그래서 결국, 전이학습이라는 방식을 채택하게 되었다.
전이학습
전이학습이 무엇인지부터 간단하게 알아보도록 하자. 전이학습(Transfer Learning)이란, 기존에 대형 이미지(ImageNet 등)로 학습된 모델을 가져와서 우리 데이터에 맞게 이어 학습시키는 것을 말한다. 흔히, 딥러닝은 데이터가 많을 수록 좋은 결과가 나온다고 한다. 그런데 현실에서 모델을 개발하는데 ImageNet처럼 1000개의 카테고리, 120만개의 이미지를 포함하기는 정말 쉽지 않다. 아니 거의 없다.
그래서 왠만한 경우에는 직접 모델을 학습시키는 것보다 전이학습을 하는 것이 정확도가 더 좋다고 합니다. 비유하자면 15살에게 분류시키는 것(전이학습)과 3살에게 분류시키는 것(처음부터 학습시키는 것)이랄까...? 나는 3살짜리를 20살만큼 키워보려고 시도했지만, 쉽지 않아서 15살 전이학습을 사용해서 실험을 진행하고자 합니다.
전이학습 코드
저는 파이토치를 사용하여 모델을 구성하였습니다. DenseNet에서 feature를 추출하는 맨 밑 block과 밑에서 두 번째 block만 학습시키고, 나머지는 freeze 한 형태로 학습을 진행했습니다. 원래는 맨 밑 block만 학습을 진행해보려고 했는데, 위 상사분이 먼저 하시고 test 93% 나왔다고 알려주셔서, 밑에서 두 번째 block까지 freeze를 해제시켜 학습을 진행했습니다. 우선, block을 freeze 시키는 방법은 다음과 같습니다.
for i in range(len(self.model.features)):
for param in self.model.features[i].parameters():
print(f"{i}: "param)이렇게 하면, 밑 사진처럼 어느 block이 몇 번째인지를 알 수 있습니다.

가시성을 위해 맨 앞 block들만 올리겠습니다. 이후 마지막으로 써져 있는 10번, 11번 block만 남겨두고 나머지는 다 freeze합니다.
for param in self.model.parameters():
param.requires_grad = False
for i in range(9,11):
for param in self.model.features[i].parameters():
param.requires_grad = True그러면, 다음과 같이 밑의 parameter들만 trainable 해지는 것을 볼 수 있습니다.

모델이 워낙 크다보니, trainable한 부분으로 바뀌는 곳을 캡쳐했습니다.
전이학습 결과

이전 기본 CNN으로 학습시키면 test accuracy가 최대 83%였습니다. 그런데, 전이학습으로 밑 두 블록만 학습시켰을 때, 89%의 test accuracy가 나온 것을 볼 수 있습니다.
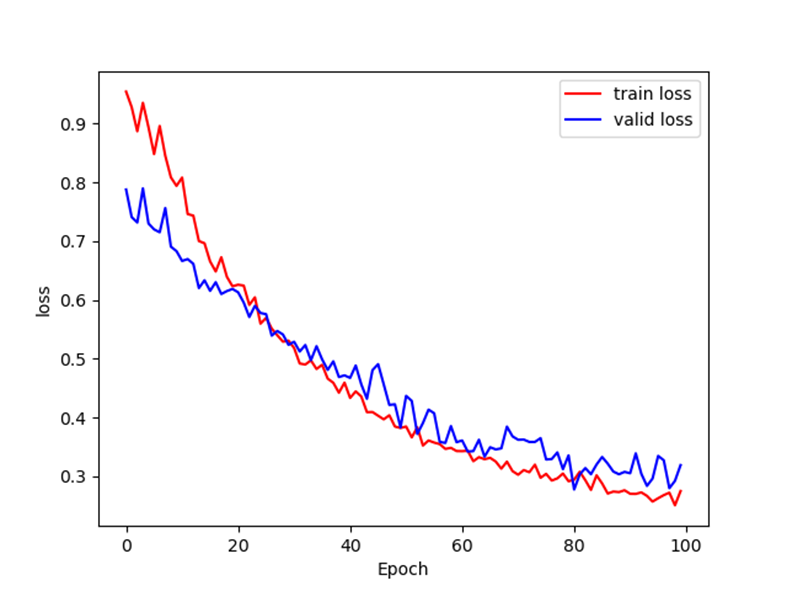

과적합도 그렇게 많이 되지 않아서, 좋은 결과를 출력한 것을 볼 수 있습니다.
여기서 한 가지 더 의문이 들었습니다. 뒤에 두 블록을 학습시켰을 때, test accuracy가 89%라면 과연 뒤에 한 블록만 학습시켰을 때는 어떨까?

신기하게도, 두 블록을 학습시켰을 때보다 0.1%올라 test accuracy가 90%인 것을 확인해 볼 수 있습니다. 보통 ResNet 혹은 DenseNet과 같은 대형 모델의 경우, 앞의 블록으로 갈수록 모든 것을 포괄하는 이미지에 대해 학습한다고 합니다. 뒤로 갈수록 우리가 가지고 있는 데이터에 맞게 학습하여 weight를 가지는 경향이 있기 때문에, 전이학습을 할 때, 전체 모델을 다시 학습시키는 것보다는 맨 밑 block만 학습시키는 것이 좋다고 합니다.
이상 Transfer learning에 대한 포스팅을 모두 마치겠습니다. 감사합니다:)
'인턴일지' 카테고리의 다른 글
| [인턴일지] 아홉번째 인턴일지 : segmentation (0) | 2023.12.06 |
|---|---|
| [인턴일지] 여덟 번째 인턴일지 : 과적합 줄이기 (2) | 2023.11.22 |
| [인턴일지] 여섯번째 인턴일지 : 7개월 중 3개월이 지난 시점의 회고록 (0) | 2023.11.07 |
| [인턴일지] 다섯번째 인턴일지 : pytorch ResNet50 grayscale 이미지 학습시키기 (0) | 2023.10.27 |
| [인턴일지] 네 번째 인턴일지: CNN(Convolution Neural Network) 직접 구성하기 (2) | 2023.10.24 |